Abstract
Text-conditioned motion generation has become a promising interface for programming humanoid robots, but current generators are often trained on human motion datasets retargeted to robot morphology. While such data provides rich semantic and kinematic priors, it does not capture the nuances of the whole-body tracking controller, including balance, contact, actuation limits, and controller-specific failure modes.
Therefore, generated motions can be semantically plausible yet difficult or impossible for the robot to execute.
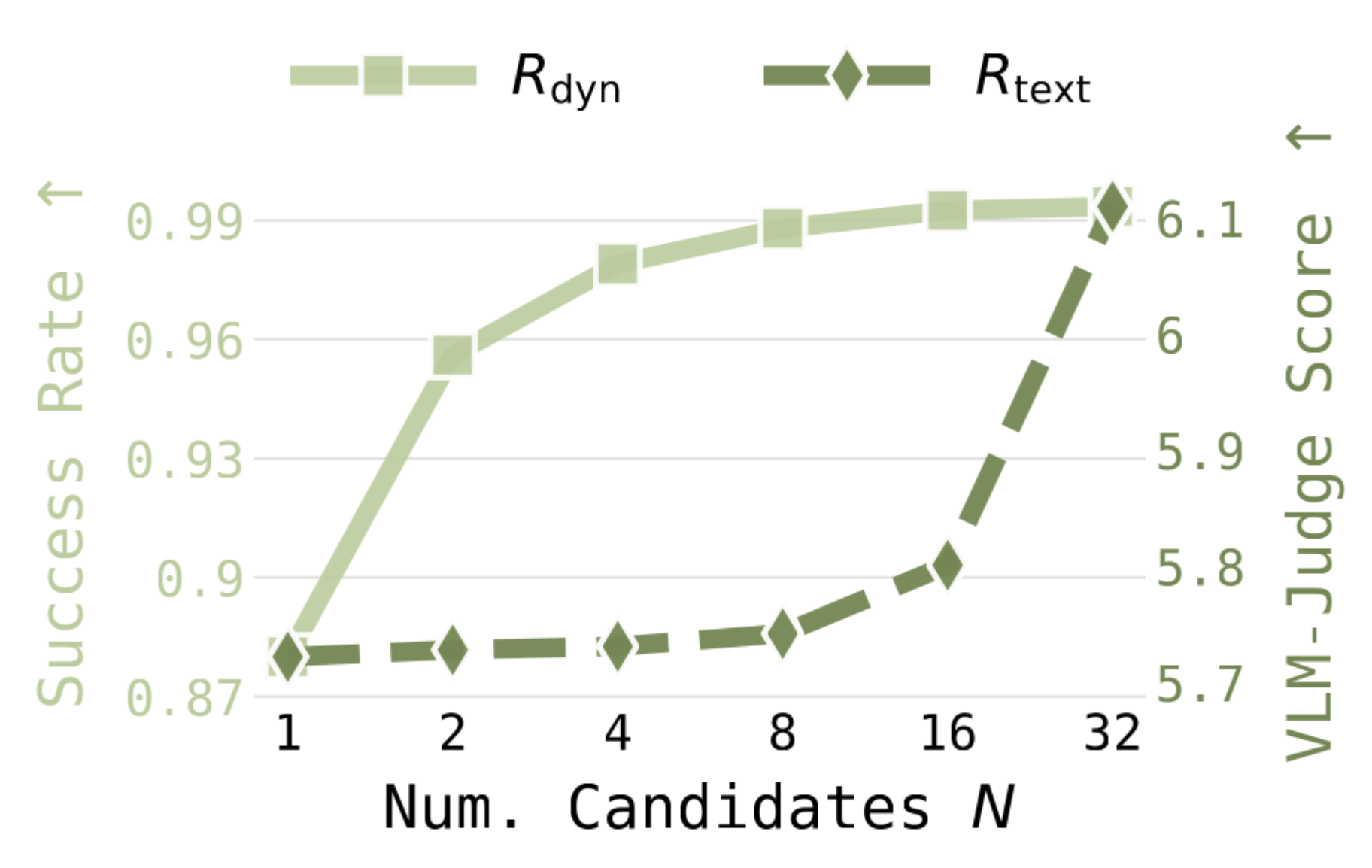
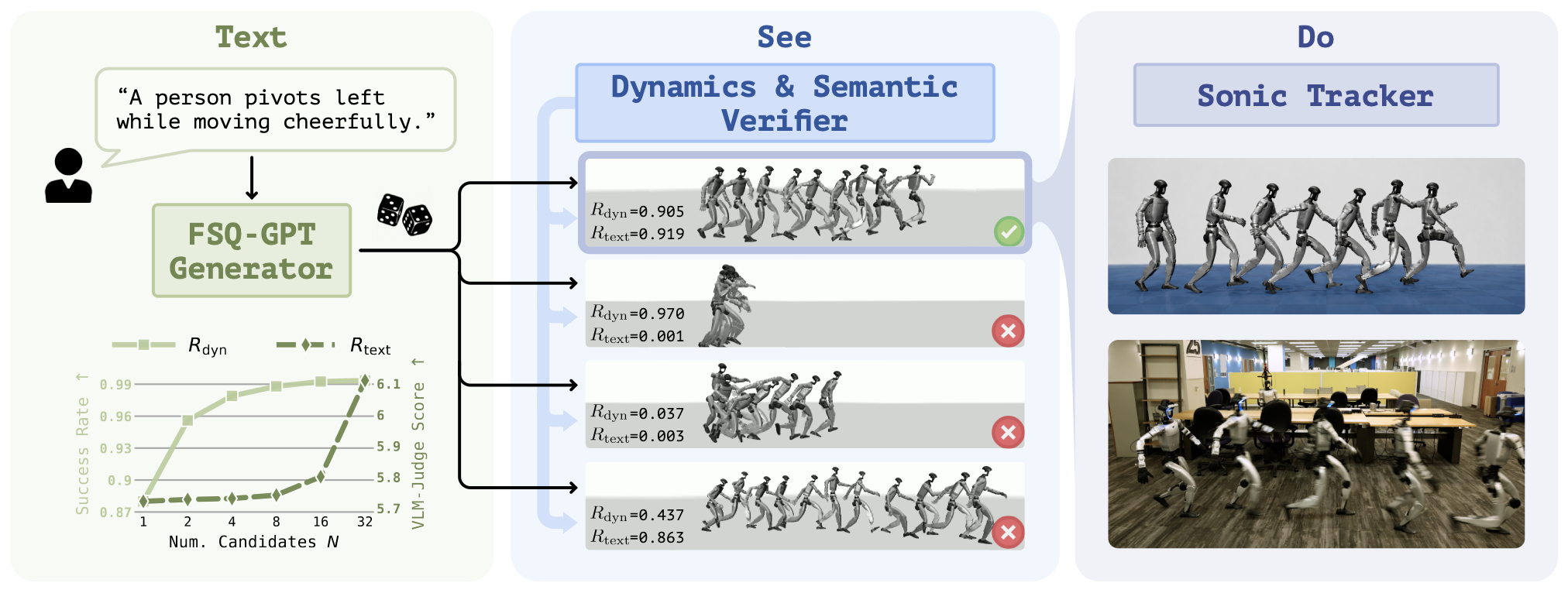
We propose TEXEDO, a test-time scaling framework for humanoid motion generation that improves motion quality without requiring a stronger underlying generator.
Given a text prompt, our method samples multiple motions from the pre-trained text-conditioned generator and selects the best executable and task-aligned motion.
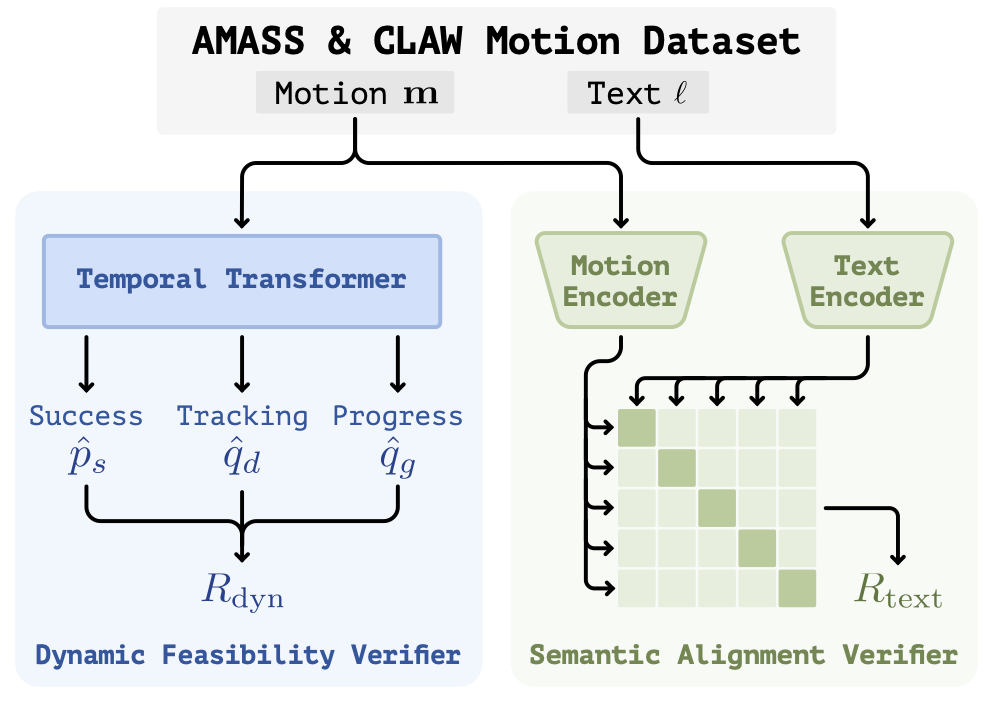
The reward model combines a dynamic feasibility verifier, distilled from whole-body tracking rollouts to predict physical executability, with a semantic alignment verifier that measures text-motion alignment in a learned co-embedding space.
Our pipeline treats dynamic feasibility as a hard constraint and semantic alignment as the selection objective within the feasible set.
Across large-scale simulation studies and real-world deployment on a Unitree G1, we show that our test-time scaling strategy consistently improves both tracking fidelity and text alignment, demonstrating that grounded verification is an effective path toward deployable language-guided humanoid motion generation.
 :
: